
There isn’t a single source of information that holistically describes flash flooding. The intention of this project is to gather and unify information about flash flooding in the US from different sources and provide the database in three different formats (i.e., comma-delimited text file, GIS shapefile, and kmz file for Google Earth™) for a variety of users who may be interested in quick-and-easy plots, detailed spatial investigations, or statistical analysis using the raw data. The database consists of 1) streamflow measurements operated and maintained by the US Geological Survey (USGS), 2) reports of flash flooding in the National Weather Service Storm Events Database, and 3) public survey responses about flash flood impacts collected during the Severe Hazards Analysis and Verification Experiment (SHAVE). The assembly of the three datasets into a unified, consistent database contains the inherent limitations associated with each one, yet the database combines the high-resolution details from SHAVE with the broad spatial coverage and event narratives from the NWS storm reports with the automated streamflow measurements from USGS to provide a more complete depiction of flash flooding across the US.
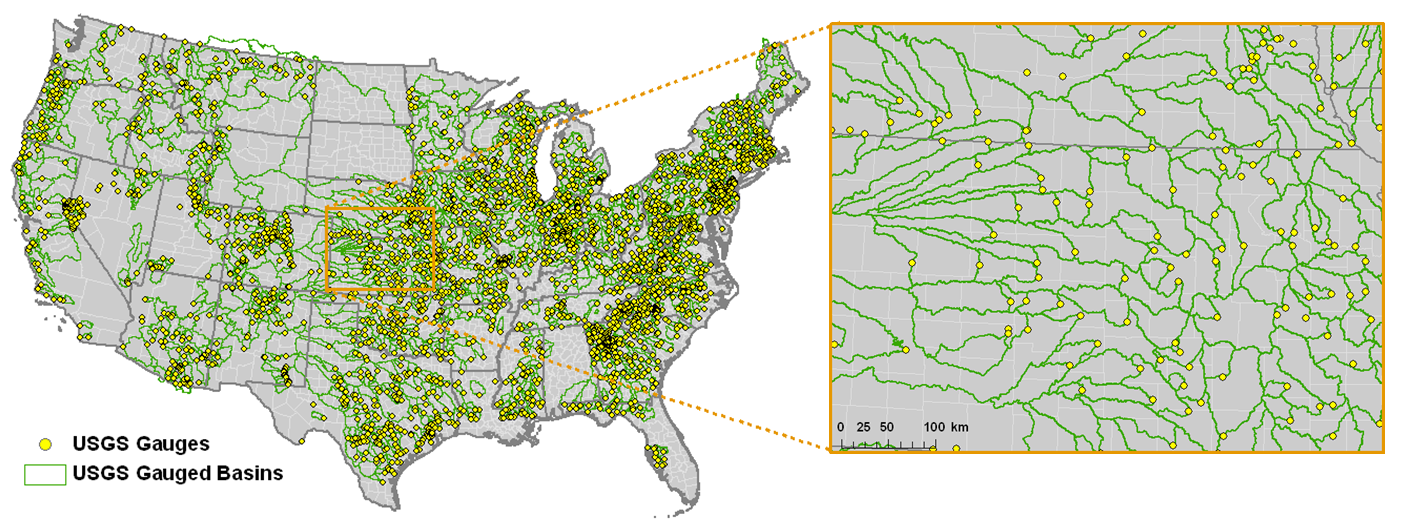
1. USGS Streamflow
Description: Each NWS office has defined stage heights associated to stream bankfull conditions, warning, minor, moderate, and major flood stages; these thresholds are chosen in coordination with the local emergency management and stakeholder community. Flood stages are determined by impacts to lives and/or property. In many cases, in the more rural areas, a bankfull stage may be significantly lower than the flood warning stage. To generate a flash flooding database from the automated reports, we identified all events that exceeded the pre-defined warning levels for each station. For each event, we provide the following information: USGS Gauge ID, latitude (decimal degrees), longitude (decimal degrees), start time (UTC) at which the flow exceeded the warning discharge threshold, end time (UTC) when the flow dropped below the warning threshold, peakflow magnitude (m3 s-1), peak time (UTC) at which peakflow occurred (UTC), and the difference between start time and peak time (in hours). This latter variable is a proxy for the time-to-rise and has been associated to the “flashiness” of the event.
Along with the events dataset, we supply metadata for each station containing static information about the USGS station’s ID, latitude (decimal degrees), longitude (decimal degrees), hydrologic unit code (HUC), agency, degree of regulation, gauge name, drainage area (km2), contributing drainage area (km2), computed flows (m3 s-1) for recurrence intervals for 2, 5, 10, 25, 50, 100, 200, and 500 yrs, and computed flows (m3 s-1) for warning, minor, moderate, and major flooding. The degree of regulation field comes directly from USGS metadata for peakflow data and has values of either “Yes”, “No”, or “Undefined”.
Usage considerations: USGS streamflow measurements benefit from automation, suffer little in the way of human-induced subjectivity, and have high temporal resolution (generally 15 min) resulting in long-term, continuous records at each gauge site. These instruments, however, require electrical power and road access for communications, regular instrument maintenance, and manual measurements to empirically establish a rating curve (i.e., the relationship between the measured stage and the desired discharge). The costs associated with these requirements imply that automated streamflow measurements are not as common in small basins where flash floods are more likely to occur. Events are thus limited to those that occurred within a gauged basin. Shapefiles of basin boundaries are helpful when studying the rainfall contributing to a USGS-gauged flash flooding event. This dataset is publicly available from the USGS at http://water.usgs.gov/lookup/getspatial?streamgagebasins. Information regarding the use of the USGS Instantaneous Data Archive (IDA) data, which is the source of the dataset described herein, is on the IDA web site at http://ida.water.usgs.gov/. Future updates (2013 and beyond) of this dataset will use the USGS Water Data for the Nation web site at http://waterdata.usgs.gov/, and information regarding the data use is available on it.
Each station’s event data and metadata are grouped by first-level, two-digit hydrologic unit code (HUC; see Fig. 2), which represents a basin scale at the regional level. Use of kmz files yields quick-and-easy displays, while the provision of shapefiles enables more in-depth spatial analysis using GIS software. The comma-delimited files can be read by a number of commonly available statistical software packages. Some users may also wish to access the text files directly for use in originally developed code and scripts.
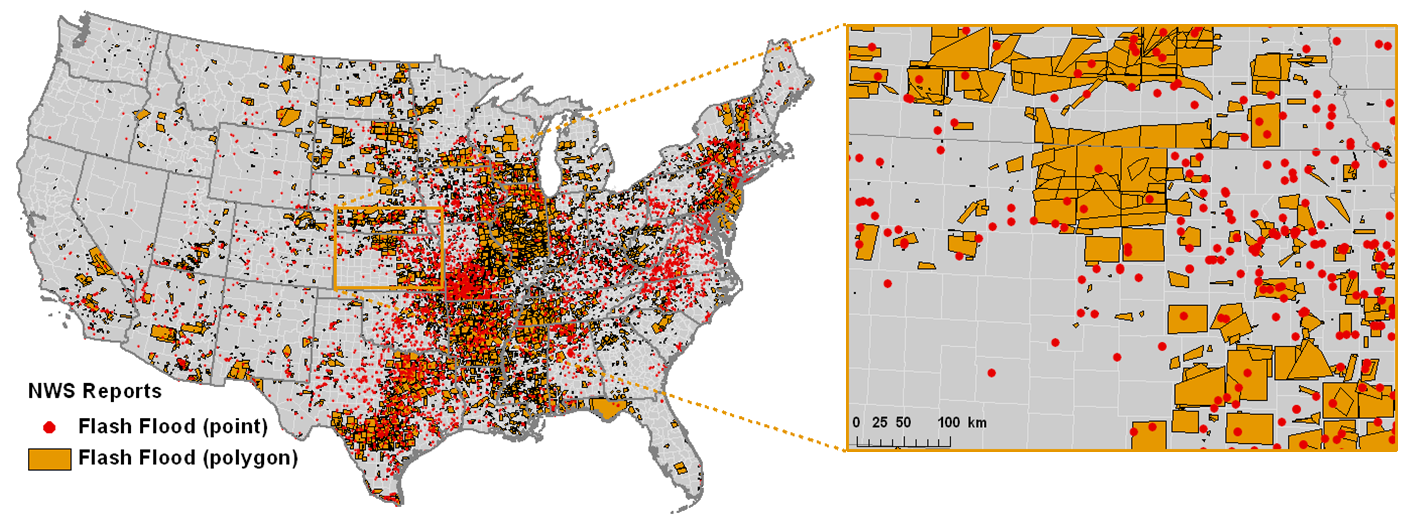
2. NWS Storm Reports
Description: Prior to 1 October 2007, NWS storm reports were recorded by county. Thus, a single data point in the dataset is representative of flash flooding somewhere within the larger county boundary. In 2006, some NWS forecast offices began experimenting with recording events by drawing bounding polygons with as many as 8 vertices around storm impacts. This protocol was implemented nationally on 1 October 2007. According to NWS Instruction 10-1605 (“Storm Data Preparation”), each report must concern a storm that posed a threat to life or property and had moving water with a depth greater than 0.15 m (6 in) or standing water with a depth of more than 0.91 m (3 ft). Each report also must contain a unique ID, the three-letter abbreviation of the NWS forecast office (WFO) who reported the event, the beginning and ending time of the event in local standard time, state, county, NWS region, direct/indirect fatalities and injuries (if applicable), a dollar estimate of property and crop damage (if applicable), details about the event including its cause (e.g., heavy rain), source of report (e.g., law enforcement), event and episode narratives, and vertex coordinates in decimal degrees of latitude and longitude as well as the range (mi) and azimuth (e.g., NE) from the nearest defined placename.
Usage considerations: Usage considerations: The NWS reports are recorded by operational forecasters who monitor their respective regions of responsibility across the US during all hours of the day, all days of the year. The reports can come from trained spotters, emergency management personnel, law enforcement, and the public. Big, high-impact events that may not have been reported in the USGS dataset are much more likely to be contained in this dataset. Users can assume that a suspect event (e.g., from a model forecast) that was not recorded in the NWS dataset either didn’t occur or occurred in a sparsely populated region without reliable observers. When studying the rainfall for a specific event, considerations for the time and spatial displacement of the causative rainfall must be made.
NWS flash flooding reports are presented in three different file formats, consistent with the USGS portion of the database. Some of the event narratives were too long to fit within the maximum allowable character fields in the kmz and shapefile formats. The full details are preserved in the comma-delimited text files. Point- and polygon-based are stored in separate files because an individual shapefile can only contain one type of geometry (either point or polygon). Only minor alterations have been made to the original Storm Data reports. A unique ID number has been added to each report, along with UTC start and end times and UNIX epoch start and end times. Additionally, some “polygon” reports originally contained only two vertices. In those cases, a box was drawn around the original report such that the original two vertices make up the diagonal of the new report.
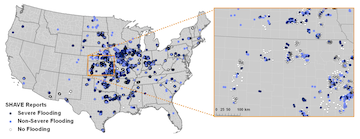
3. SHAVE
Description: Flash flood data were added to the Severe Hazards Analysis and Verification Experiment during the summers of 2008-2010 (May through Aug). Overall, 9,369 reports were collected during SHAVE. Details obtained directly from the public through a questionnaire include the depth and movement of flood waters, lateral extent of water out of the stream, incidence of rescues and evacuations, start and end times of impacts, respondent-estimated frequency of event, and types of impacts. Entries often include detailed comments to assess the uncertainty and validity of the reports as well as to include other anecdotal responses that didn’t readily fit into one of the survey questions. The SHAVE dataset was post-processed in order to better classify the impact types and to incorporate additional geographical attributes into each report, including land use, local upslope, contributing drainage area, compound topographic index, and population density (see Calianno et al., 2012 for details).
Usage considerations: This dataset differs significantly from the others in that it is experimental, storm-targeted, and point-based. The objective of the data collection was not to encapsulate all flash floods occurring across the US during the experimental period, but rather focus on individual storm events and collect very detailed, high-resolution information. In the NWS and USGS datasets, users can assume that a missing report can typically be considered as a non-event, unless there were no observers nearby or there was an instrument or communications failure. The same assumption does not apply to the SHAVE dataset. We have thus recorded and supplied all instances of reports of “no flooding” in the dataset. In fact, this class comprises 73% of the total reports. These reports must be used when determining when an event (e.g., from a model forecast) did not occur. Users are encouraged to read the SHAVE metadata file to access additional details about each field in the reports; all of which are available in the kmz, shapefile, and comma-delimited text formats for each 2-digit HUC.
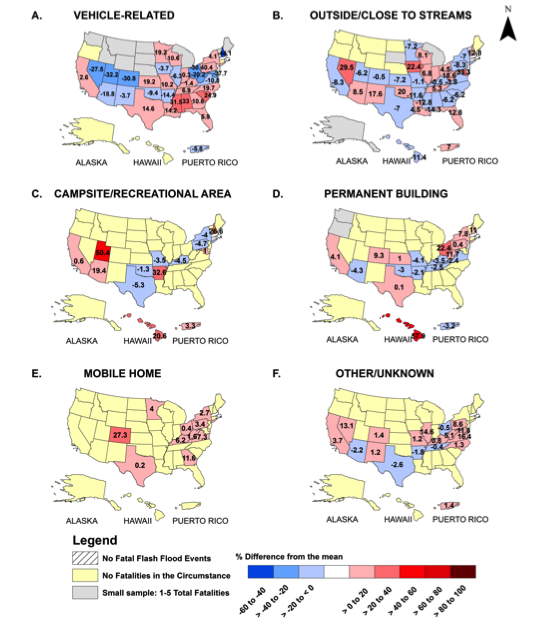
4. Fatality Circumstances
Description: The Storm Data publication maintained by the NWS includes a fatality file (available at NCDC Storm Events) describing the details of the deaths caused by flash flooding. The narratives of the descriptions have been evaluated in order to classify each fatality caused by flash flooding in the following categories: vehicle-related, outside/close to stream, campsite/recreational area, permanent building, mobile home. These classifications are now provided for 1075 fatalities from flash flooding events recorded by the NWS from 1996 to 2014 across the United States. Additional information provided in the original file includes the age and gender of the victim, the year and month of the fatality, the state and county that the fatality occurred within, and the local beginning and end times of the flash flooding events.
Usage considerations: The fatality circumstance file is designed to be comprehensive in that it should contain all flash flooding fatalities across the U.S. from 1996-2014. The event reports are provided by individual NWS offices, thus the details provided vary from case-to-case. Of the 1075 entries, 61% are related to vehicles. The sample sizes are much smaller for the camping/recreational areas, permanent buildings, and mobile homes categories, so caution should be exercised when examining those fatality circumstances.
Downloads
FLASH Flood Observation Database – 2016 v1
FLASH Flood Observation Database – 2013 v1
FLASH Flood Observation Database – 2011 v1