
What fraction of the US population is within x kilometers of a weather radar?We can answer this question for the lower 48 states from the w2merger caches, a grid of US population density and a digital elevation map (terrain) data. The WDSS-II program is called coverageStats and I ran it like this:
coverageStats -i $HOME/.w2mergercache/_55.000_-130.000_500.000___NMQWD_0.010_0.010___33_3500_7000/ -E conus/conusterrain.nc -P conus/nap10ag.asc.gz -o `pwd`/coverage -h 0:5 --verbose
I am defining that some place is covered by a weather radar if it is scanned by that radar at a height of below 5km above ground level. The population density data is in Esri Grid format from Columbia University. The digital elevation data is from the USGS (the gtopo30 dataset) and has been converted to netcdf using the WDSS-II tool topoBrea. Radar coverage information comes from the MRMS CONUS 1km resolution cache (created using createCache).
Here’s what the result looks like:
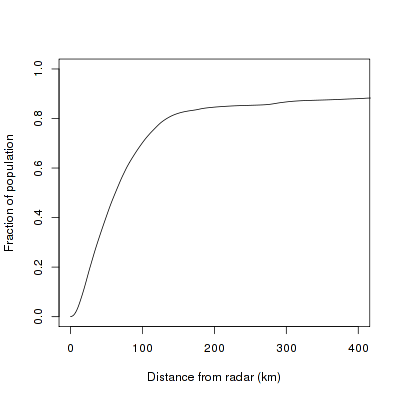 70% of the US population is covered by a weather radar that is less than 100 km away. A little less than 20% of the US population is not covered, or is covered by a radar beam that is at a height more than 5 km. Note that these numbers take beam-blockage into account.
70% of the US population is covered by a weather radar that is less than 100 km away. A little less than 20% of the US population is not covered, or is covered by a radar beam that is at a height more than 5 km. Note that these numbers take beam-blockage into account.
Here’s a map of what area is covered at what height.
 One thing to realize is because I started with the MRMS cache, parts of Canada are included in these statistics.
One thing to realize is because I started with the MRMS cache, parts of Canada are included in these statistics.
If you want to try out different assumptions (What if I drop radar X? Do not consider Department of Defense radars? Use height of 3km to 5km? etc.), feel free to run coverageStats yourself.